A paragraph of plain text becoming broadcast-quality narration in under two seconds. That was a 2023 demo reel. In 2026 it is the table-stakes expectation, and the platforms that own this category are no longer racing on realism alone. They are racing on language depth, on latency for voice agents, on whether the editor experience survives a 40-minute audiobook chapter, and on whether the credit math holds up after a year of production. Six platforms ran through the same gauntlet, with verified pricing and the editorial reads that actually surface during a real project.
Three Production Pressures That Sort the Field
AI text-to-speech is no longer a single category. Different pressures break different tools. The frame below replaces a generic feature checklist with the three failure modes that actually surface once a script leaves the demo page.
Production Pressure
What It Tests
Why It Matters in 2026
Long-form prosody
Naturalness across 10+ minute reads at production volume
Demos hide on short clips; fatigue exposes weakness fast
Cross-lingual stability
Timbre and accent fidelity across non-English output
Localization fails fastest when accents drift mid-video
Inference latency at concurrency
Time to first audio under real load
Voice agents below 250 ms feel human; above, they don't
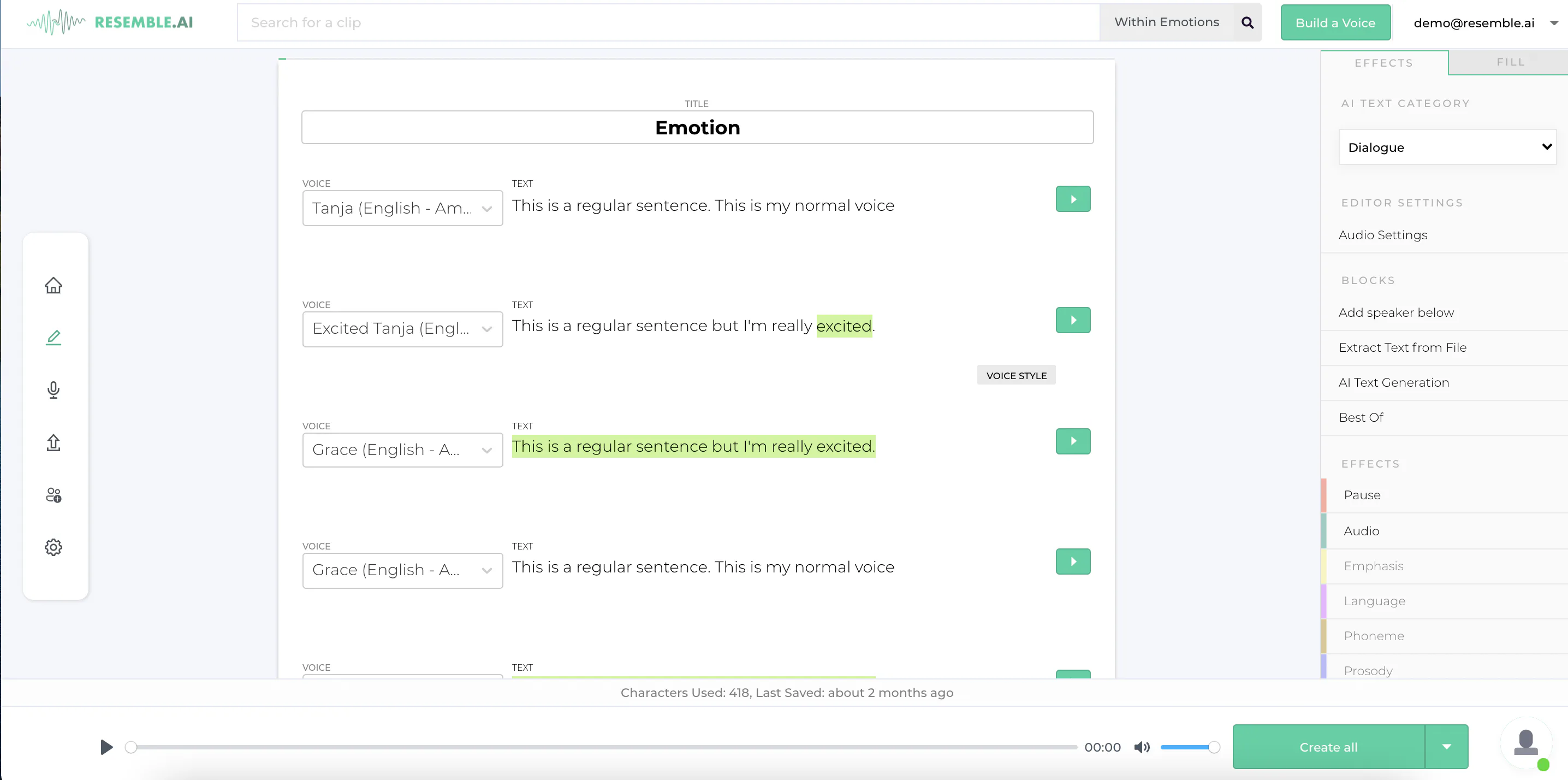
Resemble AI
TTS Specialist with a Built-in Audit Trail
Resemble runs a full text-to-speech engine with emotional control, real-time generation, and a 60+ language catalog, then layers voice cloning on top as a power-user option. What pulls Resemble ahead of pure-TTS competitors is the ethics infrastructure: an AI Watermarker that embeds detectable signatures in every generated clip, and a Deepfake Detector now available on the Flex Plan covering audio, video, and image detection. For regulated industries shipping branded narration at scale, the audit trail is the product.
★★★★☆
Editorial Score
9.0 / 10
Strongest compliance posture among TTS specialists
Snapshot: Resemble Capability Profile
Capability
Detail
Rapid Voice Clone
Created quickly from short audio sample, fast prototyping
Professional Voice Clone
Higher fidelity, requires more training data, production-grade
Language coverage
60+ with cross-lingual voice transfer
Real-time API
Low-latency streaming for conversational AI
Deepfake Detector
Audio, video, and image detection (Flex Plan)
Mobile deployment
Native neural voices on Android and iOS SDKs
Integration partners
OpenAI GPT-4, Twilio, custom enterprise pipelines
Pricing Structure (Verified May 2026)
Plan
Billing Model
What Unlocks
Notes
Free Credits
Trial credits on signup
Voice generation testing
No commercial output on trial
Flex
Usage-based credit packs
Deepfake detection access, API scaling
Sales engagement at $500+/mo
Subscription
Tiered monthly plans
Custom voice cloning, API support
Multiple tier levels
Volume Pricing
Negotiated
Discount triggers at higher spend
Sales-assisted
Enterprise
Custom contracts
SSO, model finetuning, on-premise, SLAs
Higher concurrency caps
Per Resemble AI pricing page documentation, May 2026.
Where Resemble Wins, Where It Stalls
Strengths
Honest Limitations
Audit-trail features unmatched in the category (watermarker + detector)
Pricing structure less transparent than per-character competitors
Real-time voice-to-voice conversion deployed in production
Per-credit costs add up faster than per-character APIs at small volume
Native mobile neural voices reduce backend processing cost
Smaller community voice library than ElevenLabs or Fish Audio
Used in enterprise sales, customer service, and entertainment pipelines
Cartesia ships text-to-speech models built on State Space Model architecture rather than transformers, and the result shows up where it matters most: time to first audio. Sonic 3 hits roughly 90 ms model latency, four times faster than the next alternative per Cartesia's own benchmarks. For voice agents, IVR systems, and live-conversation TTS, that gap is the difference between a conversation feeling natural and feeling like a phone tree. Sonic 3 handles 40+ languages with embedded tags including [laughter], emotion descriptors, and fine-grained speed and volume dials directly inside the text input.
★★★★½
Editorial Score
9.2 / 10
Best-in-class TTS latency for real-time agent workloads
Snapshot: Sonic 3 Technical Profile
Specification
Value
Model architecture
State Space Model (linear scaling, not transformer quadratic)
Time to first audio
~40 to 90 ms, four times faster than next alternative
Voice clone sample
3 seconds minimum (Instant Voice Cloning)
Language coverage
40+ with cross-lingual generation
API rate
~$46.70 per 1M characters on Sonic 3
Concurrent streaming
WebSocket multiplexing across dozens of streams
Open-source release
English-only variant available for self-hosting
Plan Breakdown (Verified May 2026)
Plan
Monthly
Credits
Cloning Tier
Concurrency
Free
$0
10,000
Limited
Trial only, no commercial use
Pro
$5
100,000
Instant Voice Cloning
3 parallel requests
Startup
Higher tier
Higher pool
Pro Voice Cloning (higher quality)
Elevated
Enterprise
Custom
Custom
Pro cloning + custom models
Custom SLA, on-prem option
Per Cartesia pricing page, eesel AI breakdown, and Inworld benchmark report, March 2026.
Where Cartesia Wins, Where It Stalls
Strengths
Honest Limitations
Lowest raw latency in the category for voice agents (~90 ms)
Voice naturalness ranks #10 on Artificial Analysis ELO; capable but not flagship
3-second clone sample is the lowest bar of any major platform
Smaller voice library than ElevenLabs or Fish Audio
State Space Model architecture reduces per-request infra cost at scale
English remains noticeably stronger than the 40 non-English languages
Free tier with 10,000 credits genuinely useful for prototyping
No commercial rights on Free tier
CAMB.AI (MARS Family)
Broadcast-Grade Multilingual TTS
CAMB.AI's MARS family of speech models powers something the consumer platforms have not done at scale: real-time TTS for live broadcasts. Eurovision Sport partnered with CAMB.AI to deliver live subtitling and synthesized commentary for the Milano Cortina 2026 Paralympic Winter Games. Ligue 1 now broadcasts Italian-language expressive multi-speaker football commentary via the platform. Major League Soccer uses CAMB.AI for sub-second multilingual streams. The four-model MARS lineup spans 150+ languages, from MARS-Nano running on-device at 50 ms latency to MARS-Instruct with director-level emotion control for cinematic narration.
★★★★☆
Editorial Score
8.8 / 10
Only platform with proven broadcaster deployment at scale
Snapshot: MARS Model Family
Model
Parameters
Latency / Quality Spec
Built For
MARS-Flash
600M
~100 ms time-to-first-byte
Real-time conversational AI
MARS-Pro
600M
0.87 WavLM speaker similarity
Long-form expressive narration
MARS-Instruct
1.2B
Director-level emotion controls
Cinematic dubbing
MARS-Nano
50M
~50 ms TTFB on-device
Offline deployment, no internet
Production Deployments (Public)
Customer
Use Case
Scope
Eurovision Sport
Live subtitling and dubbing for Paralympic Winter Games 2026
Milano Cortina event coverage
Ligue 1
Italian multi-speaker football commentary, live
French league for Italian audience
Major League Soccer
Sub-second live multilingual streams
MLS multilingual broadcasting
IMAX (Three)
First AI-dubbed IMAX release in Mandarin
Delivered within 48 hours
Per CAMB.AI public case studies and Eurovision Sport press, January to May 2026.
Where CAMB.AI Wins, Where It Stalls
Strengths
Honest Limitations
Only platform with proven broadcaster deployment at scale
Solo creator tier less visible than enterprise messaging
150+ languages cover 99% of the world's speaking population per CAMB.AI claims
Pricing requires direct quote for production volumes
MARS clone from 2 to 3 second samples preserves emotion across languages
GPU-based pricing scales predictably with utilization
Smaller community of independent developers than Cartesia
HeyGen
Text-to-Speech Bundled with Avatar Video
HeyGen sells AI avatar video, but the text-to-speech engine underneath is treated as a first-class feature, not an afterthought. Type a script into the editor and HeyGen renders synthesized narration in 175+ languages with automatic lip-sync to the on-screen avatar. The Avatar V model needs only a 15-second recording for a digital twin, with the highest face-similarity score in the avatar category at 0.840 per AIvideopicks April 2026 testing. Compared to Synthesia, HeyGen stands out when the priority is fast multilingual avatar content with natural voice, face, and lip-sync alignment. The Creator plan at $24 per month annually includes the TTS engine and unlimited base videos at 1080p, though independent reviewers including AIimageToVideo flag accent drift in non-English voice output
★★★★☆
Editorial Score
8.5 / 10
Strongest combination of TTS and avatar in one pipeline
Snapshot: TTS and Avatar Specs
Component
Detail
Avatar V model
15-second recording generates a digital clone
Face similarity score
0.840, highest in the avatar category per AIvideopicks
Language coverage
175+ for translation with lip-sync
Custom Voice Clone
$99/year add-on per cloned voice
Premium Credit cost
20 credits per minute of Avatar IV/V output
Compliance
SOC 2 Type II, GDPR, CCPA, EU AI Act
Plan Breakdown (Verified April 2026)
Plan
Annual Rate
Monthly Rate
Premium Credits
Notable Unlocks
Free
$0
$0
0
3 videos/month, 720p, watermark
Creator
$24/mo
$29/mo
200/mo
Unlimited base videos, 1080p, TTS in 175+ languages
Pro
Monthly only
$99/mo
2,000/mo
Highest individual credit allocation
Business
$124/mo + $20/seat
$149/mo + $20/seat
1,000 shared
4K, SCORM, 60-min videos, integrations
Enterprise
Custom
Custom
Custom
API, SSO, dedicated infrastructure
Per Arcade blog and AIvideopicks April 2026 plan breakdowns. API free tier was removed in February 2026.
Where HeyGen Wins, Where It Stalls
Strengths
Honest Limitations
TTS and avatar in one pipeline removes production handoffs
Premium Credit system burns fast on Avatar IV/V workflows
175+ language TTS with lip-sync at consumer pricing
Accent drift reported on non-English synthesized voices
Strong compliance posture for enterprise procurement
API free tier was removed in February 2026
Avatar V from 15-second sample is the lowest bar in the avatar category
Effective cost per minute exceeds sticker price after credits exhaust
DupDub
All-in-One Text-to-Speech and Dubbing Studio
DupDub sits in an interesting position. The platform leads with text-to-speech (700+ stock AI voices across 130+ languages) and bundles dubbing, talking avatars, and video translation in one dashboard. The Personal plan at $11 per month opens commercial use; Professional at $30 per month adds extended capacity. Voice realism trails ElevenLabs by a perceptible margin on dramatic narration per Kripesh Adwani's December 2025 review, but holds up cleanly for explainer, training, and short-form content where the alternative is hiring six voice actors across six languages.
★★★★☆
Editorial Score
8.3 / 10
Best price-to-feature ratio for solo multilingual TTS work
Snapshot: DupDub Capability Inventory
Tool
Function
Standout Detail
Voice Library (TTS)
700+ stock AI voices for text input
130+ languages and accents
Voice Cloning
Custom voice from 30 sec to 2 min sample
0.1 credits per second for cloned and ultra voices
Video Dubbing
Translate and lip-sync across languages
90+ language targets, decent lip-sync
AI Talking Avatar
Avatar video from script
Combines with cloned voice on timeline
Transcription + Subtitles
Multilingual transcripts and captions
Aligned to video timeline automatically
API
Developer access for embedding
~200 ms response, 300 GB enterprise storage
Plan Tiers (Verified March 2026)
Plan
Monthly USD
Best For
Hard Limit
Free
$0
3-day trial, ~10 credits
No commercial export
Personal
$11
Solo creators, short-form content
Lower credit allowance
Professional
$30
Frequent creators, longer projects
Higher credits + storage
Ultimate
$110
Power users, larger asset libraries
Premium credit limits
Scale (companies)
$300
Small teams collaborating
Team workspace seats
Business / Custom
Custom
Enterprise deployment
API, brand voices, dedicated support
Per Software Finder, Fahimai, and Toolsforhumans reviews, December 2025 to March 2026.
Where DupDub Wins, Where It Stalls
Strengths
Honest Limitations
700+ TTS voices across 130+ languages on the Personal tier at $11/mo
Voice realism trails ElevenLabs perceptibly on dramatic narration
Cross-lingual voice transfer keeps timbre intact across languages
Lip-sync described as decent rather than perfect
Avatar plus dubbing plus TTS bundled removes a five-tool stack
Credit math less predictable than per-character pricing
Canva and GPTs integrations connect into design workflow
Storage limits tighter on lower tiers
WellSaid Labs
Enterprise Studio TTS with Compliance Pedigree
WellSaid Labs is the corporate-credentialed answer to consumer text-to-speech generators. The platform's 60+ voices were recorded by professional voice talent and refined with neural fine-tuning, and the company holds SOC 2 Type II and ISO 27001 certifications that consumer-tier rivals cannot match. The honest limitation: voice cloning is gated behind Enterprise pricing per Voicestars and Fahimai 2026 reviews, and the Maker tier opens at $49 per month. For L&D teams at regulated firms producing English-dominant narration, the compliance trade is worth the markup. For solo creators, the same budget buys substantially more flexibility elsewhere.
★★★★☆
Editorial Score
7.8 / 10
Compliance pedigree consumer rivals cannot match, at a price
Plan Breakdown (Verified May 2026)
Plan
Approx Rate
Per Seat / Month
Voice Cloning
Best Fit
Free Trial
$0
7 days
None
Pre-selected voices only
Maker
~$49
Individual
Not available
Solo creators, 5,000-char clips
Creative
~$99
Individual
Not available
Adds commercial rights, expanded voice library
Team
~$199
Per-creator collaborative
Not available
Team controls, priority support, 30 hrs audio
Enterprise
~$1,200+/mo
Custom
Yes, 30 min training audio required
API, SSO, SOC 2 documentation
Per Vendr and VisionStack AI 2026 procurement audits, May 2026.
Snapshot: Studio Voice Capabilities
Capability
WellSaid Detail
Voice library
60+ professionally recorded voices with neural fine-tuning
Languages
English-dominant; 15 languages per KHABY AI audit
Voice cloning
Enterprise tier only; 30 minutes of clean training audio required
API access
Standard tier permits 100 requests per second
Compliance certifications
SOC 2 Type II, ISO 27001
Export formats
MP3 and WAV download
Where WellSaid Wins, Where It Stalls
Strengths
Honest Limitations
Compliance pedigree consumer rivals cannot match (SOC 2, ISO 27001)
Voice cloning gated behind Enterprise is the structural weakness
Professionally recorded voice catalog reduces output variability
$49 entry tier costly vs $5 to $22 from competitors
Team collaboration designed for L&D and corporate workflows
English-dominant; weaker fit for global multilingual content
No native voice cloning until an enterprise contract is signed
Editorial Decision Matrix
Pick by Where the Project Breaks First
AI text-to-speech has matured past the point where a single generalist recommendation makes sense. The matrix below maps situations to picks based on the failure mode most likely to surface in production, not on which voice sounds prettiest in a one-line demo.
Situation
Recommended Pick
Why It Wins
Real-time TTS agent below 250 ms first-audio
Cartesia Sonic 3
~90 ms latency, WebSocket multiplexing, State Space Model
Live broadcast TTS or sports commentary
CAMB.AI MARS-Flash
Proven at Eurovision Sport, Ligue 1, MLS
Avatar video with synced TTS narration
HeyGen Creator
175+ language lip-sync at $24/mo annual entry
All-in-one creator TTS, dubbing, and avatars
DupDub Personal
700+ voices plus dubbing plus avatar at $11/mo
Regulated industry corporate narration
WellSaid Labs Team
SOC 2 Type II and ISO 27001 certifications
Enterprise TTS with deepfake audit trail
Resemble AI Flex
Watermarker plus Deepfake Detector built-in
Game character voice generation
Resemble or Cartesia
Real-time generation with fine-grained emotion controls
AI text-to-speech split into two distinct markets in 2026. One sells per-character API access to developers building voice agents and translation pipelines, where the platform lives or dies on latency and unit economics. The other sells finished video and studio workflows to creators and L&D teams, where it lives or dies on the editor experience. Resemble, Cartesia, and CAMB.AI compete in the first market. HeyGen and DupDub compete in the second. WellSaid Labs sits adjacent to both, trading flexibility for compliance documentation.
The brutally honest line is that no platform wins across every use case. Pick by where the project actually breaks first. If latency is the failure mode, Cartesia answers it. If language coverage is the failure mode, CAMB.AI answers it. If procurement compliance is the failure mode, WellSaid Labs answers it. The category has matured past the point where a generalist recommendation makes sense, and the TTS projects that go sideways are almost always the ones that picked by reputation rather than by failure mode.