
So how does a content creator actually use AI to write a blog post in 2026? Not the marketing-page version, where one prompt produces a publishable masterpiece and everyone goes home early. The real version is messier, funnier, and depends entirely on which stage of the writing process is being discussed. Four tools share the work. Half of them quietly hallucinate. The writer still ends up doing most of the editing. The interesting story this year is not what AI can write. It is how the workflow itself has been rebuilt around the realization that no single tool does this job well.
The new blog workflow
The 2024 workflow (paste prompt, edit output) is dead. Two things killed it. Helpful Content updates and SpamBrain rewrites systematically demoted thin AI output between late 2023 and 2025. Then AI search itself shifted: ChatGPT, Perplexity, Google AI Overviews, and Gemini now answer a meaningful share of informational queries before the user sees a blue link. A blog post in 2026 needs to rank on Google AND get cited inside AI answers to matter.
What replaced the single-tool workflow is a layered stack. Topic ideation runs through Frase or a Surfer Topical Map. Brief generation lives in Frase or a custom Claude prompt. Drafting splits between Claude and ChatGPT depending on whether the piece needs craft or multimodal. Optimization happens in Surfer's Content Editor. The newcomer: GEO scoring, where Frase and Surfer added dedicated modules in 2025 and 2026. Editing stays human, because that is where the value lives.
AI compresses pattern-matching and exposes craft. The creators winning are not publishing faster. They are choosing better.
Where AI saves time
Time savings concentrate on bounded, pattern-driven work. They disappear (or invert) on anything requiring verifiable claims, judgment, or genuine expertise. The chart maps efficiency by stage. The negative bar on fact verification is the most important number here: every minute saved on first draft is partially repaid on the back end if the draft contains fabricated statistics or hallucinated studies.
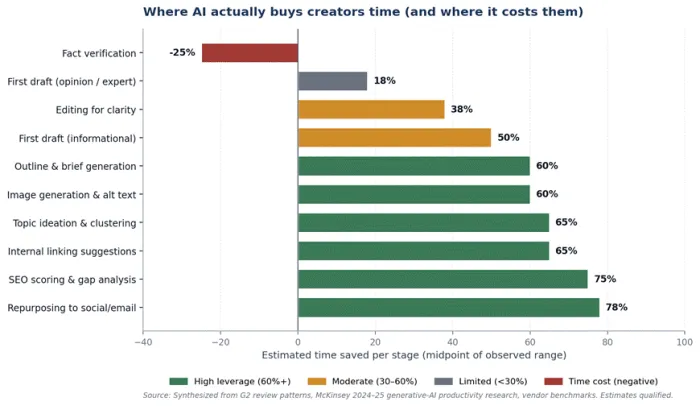
Figure 1. Time saved per workflow stage. Negative bar reflects that fact-checking AI output costs more than fact-checking a human draft of the same length.
The tools, reviewed honestly
Each section opens with a one-line intro of what the tool actually is, followed by a blunt take and a comparison table against two specific competitors. The focal tool sits in the highlighted column.
Jasper Pro
An AI writing platform purpose-built for marketing teams, with brand voice training as its anchor product.
The brand voice engine is genuinely the best in the category. Train it on five to ten samples and Jasper holds tone across writers and formats more reliably than any system prompt hacked together in Claude or ChatGPT. The catch: Pro caps long-form lookback at 1,500 characters, which sounds harmless until a 2,500-word post forgets its own intro. Worth it for in-house teams of three or more, overkill for everyone else.
| Dimension | Jasper Pro | ChatGPT Plus | Writer.com |
|---|---|---|---|
| Monthly cost | $59 / seat (Pro) | $20 / user | Custom (enterprise) |
| G2 / Capterra | 4.7 / ~4.8 (1,700+) | Not listed on G2 | 4.5 / ~4.5 (250+) |
| Brand voice | Best in category | ~70% via custom GPTs | Strong, governance-focused |
| Long-form depth | 1,500-char lookback | 1M context window | Full-document handling |
| Hallucination control | Knowledge Base (5 assets on Pro) | Web grounding + memory | RAG + brand controls |
| Best fit | Marketing teams of 3+ | Solo creators, multimodal | Regulated industries |
Surfer SEO
A content optimization platform that scores drafts against top-ranking SERP pages in real time. Not a writer.
The Content Editor pulls top-ranking pages for the keyword, identifies patterns, and gives a real-time score from 0 to 100. The trap most creators fall into is treating that score as a ranking predictor. It is correlation, not causation. Score-85 articles routinely rank at position 15. Score-55 articles rank top three. Where Surfer earns its money is the Content Audit and Topical Map, not the Editor.
| Dimension | Surfer SEO | Clearscope | Frase |
|---|---|---|---|
| Monthly cost | $89 (Essential) | $350+ (Essentials) | $15-45 |
| G2 / Capterra | 4.8 / 4.9 (537) | 4.6 / 4.5 (~140) | 4.8 / ~4.8 (~300) |
| Core function | SEO scoring + audit | Term recommendations | Briefs + GEO score |
| AI-search tracking | Add-on (Scale AI) | Limited | Built-in (Solo+) |
| Niche topics | Breaks under 5 SERP competitors | Same limitation | Brief generation still works |
| Best fit | Audits + cluster planning | Premium accuracy | Solos + GEO focus |
Frase
A research-and-brief tool that became the most relevant 2026 platform thanks to GEO scoring and AI Search Tracking.
Frase grades drafts against patterns AI engines reward (clear definitions, structured factual claims, citation-worthy specificity) and tracks daily whether URLs show up inside ChatGPT, Perplexity, and Google AI Overviews answers. This is the single most important feature any blog tool shipped in 2025, and most creators have not noticed yet. Drafting still collapses past 1,500 words. Use Frase for briefs, finish in Claude.
| Dimension | Frase | Surfer SEO | MarketMuse |
|---|---|---|---|
| Monthly cost | $15 (Solo) - $45 (Basic) | $89 (Essential) | $7,000+ / year |
| G2 / Capterra | 4.8 / ~4.8 (~300) | 4.8 / 4.9 (537) | 4.6 / 4.5 (~120) |
| Brief generation | ~60-90 sec | ~3-5 min | ~5-10 min |
| GEO / AI search | Built-in (the 2026 differentiator) | AI Tracker add-on only | Not native |
| Topical authority | Basic clustering | Topical Map (strong) | Deep modeling (enterprise) |
| Best fit | Solos chasing AI citations | Optimization-led teams | Enterprise content ops |
Claude Pro
A general-purpose AI model that has become the long-form drafting standard for serious content creators.
The model itself, Opus 4.6 and Sonnet 4.6, is what every other tool on this list compares itself to. Tom's Guide's 2026 head-to-head against ChatGPT named the difference a sophistication gap: Claude produced what they called lived-in quality while ChatGPT defaulted to academic frameworks and AI slop. The 200K context window on Pro is the practical advantage for blog work.
| Dimension | Claude Pro | ChatGPT Plus | Gemini Advanced |
|---|---|---|---|
| Monthly cost | $20 (Pro), $100 (Max) | $20 (Plus) | $20 (Advanced) |
| Long-form quality | Best in class ('lived-in') | Strong but template-y | Solid, less polished |
| Context window | 200K (Pro) | 1M (Plus) | 1M (Advanced) |
| Multimodal | Limited (no native image) | DALL-E + voice + browsing | Workspace + image |
| Rate limits | Bite hard on Pro | Looser on Plus | Generous |
| Best fit | Long-form prose, briefs | Multi-format creators | Google Workspace users |
ChatGPT Plus
The multimodal generalist with the largest plugin and custom-GPT ecosystem. Strongest on image, voice, and browsing.
GPT-5.4 ships with a 1 million-token context window, plus DALL-E, voice mode, real-time browsing, and the custom GPTs ecosystem. For creators whose workflow includes podcast scripts, video outlines, or image generation in the same tool, ChatGPT is not optional. Where it loses on long-form prose is structural: the default output has a recognizable signature the industry has started calling AI slop.
| Dimension | ChatGPT Plus | Claude Pro | Gemini Advanced |
|---|---|---|---|
| Monthly cost | $20 (Plus) | $20 (Pro) | $20 (Advanced) |
| Multimodal coverage | DALL-E + voice + browsing | Limited | Workspace integration |
| Long-form prose | Recognizable AI-slop signature | Lived-in quality | Solid, mid-pack |
| Custom workflows | Custom GPTs ecosystem | Projects + Artifacts | Gems + Workspace |
| Brand voice | ~70% via custom GPTs | System prompts (per session) | Persona via Gems |
| Best fit | Multi-format creators | Long-form writers | Workspace teams |
Notion AI
A drafting layer embedded inside Notion, designed to remove context-switching for creators already living in the workspace.
Drafting quality trails Claude meaningfully. The reason it appears here anyway: for a solo creator whose research notes, brand voice docs, and content calendar already live in Notion, embedding drafting in the same workspace eliminates the six-tab context switch that fragments most workflows. The compound time savings outweigh the model-quality gap for individual workflows.
| Dimension | Notion AI | Coda AI | Standalone Claude |
|---|---|---|---|
| Monthly cost | $10 / member (add-on) | $12 / doc-maker | $20 / mo |
| Capterra rating | 4.7 (~250) | 4.6 (~50) | Not on Capterra |
| Drafting quality | Trails Claude meaningfully | Similar to Notion | Strong |
| Workflow integration | Native (Notion docs) | Native (Coda docs) | Browser tab next to notes |
| User base | Massive ecosystem | Smaller, active | N/A |
| Best fit | Solo creators in Notion | Coda power users | Notes-elsewhere workflows |
Copy.ai and the rest
A short-form copywriting platform that pivoted toward GTM workflow automation, with a regressing long-form story.
Copy.ai has shifted toward GTM workflow automation. Long-form quality has visibly regressed in late-2025 review cohorts. Writesonic, Rytr, and Anyword survive in lower or specialized tiers, but none of them displaces Claude, Frase, or Surfer for serious blog production. Anyword is the standout for conversion-optimized copy specifically.
| Dimension | Copy.ai Pro | Writesonic | Anyword |
|---|---|---|---|
| Monthly cost | $49 (Pro) | $16 (Standard) | $49 (Data-Driven) |
| G2 rating | 4.7 (~190) | 4.8 (~1,900) | 4.8 (~1,200) |
| Specialty | GTM workflow automation | General short-form | Conversion-optimized copy |
| Long-form output | Regressed in 2025 | Mid-tier | Mid-tier |
| Differentiator | Pipeline + Workflow features | Lowest viable price | Predictive Performance Score |
| Best fit | GTM teams + automation | Budget short-form | Performance copywriting |
Cost vs quality
The chart maps each tool against monthly cost and creator-perceived long-form quality. Two patterns matter. Claude Pro sits alone in the upper-left sweet spot (strong output, low cost). The lower-right region (premium price, mid-tier output) is the trap most teams of two to four people fall into when they buy ahead of their actual workflow needs.
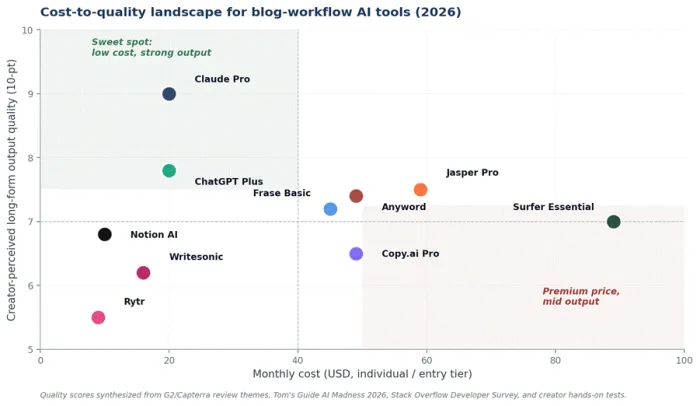
Figure 2. Cost-to-quality landscape across major blog-workflow AI tools.
Pricing reality
Sticker pricing is the shallowest layer of cost analysis. The binding constraints are word and credit caps, lookback windows on long-form, integration upcharges (Surfer when bundled with Jasper is the worst), and the absence of brand voice persistence on general-purpose models that custom GPTs paper over.
Table 1. Pricing reality. List rates reflect 2026 published prices.
| Tool | Entry tier | Working tier | Real ceiling | What the listing page does not tell you |
|---|---|---|---|---|
| Jasper Pro | $39 / seat / mo (Creator) | $59 / seat / mo (Pro) | $250+ (Business) | Pro caps you at 5 Knowledge Assets and 1,500-char lookback. Surfer integration is another $89/mo. |
| Surfer SEO | $89 / mo (Essential) | $219 / mo (Scale) | $419 (Scale AI) + $29 per AI article | Content Editor credits are the real metering unit. AI Tracker for ChatGPT/Perplexity is a separate add-on. |
| Frase | $15 / mo (Solo) | $45 / mo (Basic) | $115 / mo (Pro) + $35 SEO add-on | GEO score and AI Search Tracking are the 2026 reason to use it, not its drafting. |
| Copy.ai Pro | Free (2,000 words) | $49 / mo (Pro) | Custom (Team / Enterprise) | Free tier handles ideation only. Long-form quality has regressed in late-2025 reviews. |
| ChatGPT Plus | $20 / mo | $25–30 / seat (Team) | $200+ (Enterprise) | GPT-5.4 with 1M context. Custom GPTs replicate ~70% of Jasper's brand voice at one-third the cost. |
| Claude Pro | $20 / mo | $100 / mo (Max, 5x usage) | $200+ (Enterprise) | 200K context holds an entire brief, brand samples, and competitor articles in one prompt. |
| Notion AI | $10 / member / mo | Bundled with Business | Custom (Enterprise) | Best buy for solo creators already in Notion. Drafting trails Claude but workflow integration wins. |
Three failure modes
Hallucination
AI drafts pull from training data without source attribution. Jasper hallucinates 15-20% of factual claims in data-heavy long-form, per independent testing across late 2025. Claude and ChatGPT are better, not safe. The cost is reputational and accumulates invisibly until a single bad citation gets noticed.
1 in 6 Approximate rate at which AI drafting models still fabricate factual claims in data-heavy long-form output. Independent testing, late 2025. |
The defensive posture is mechanical: every numeric claim, every named source, every dated event treated as suspect until verified against a primary document. Knowledge Base features (Jasper) and grounded prompting with attached source PDFs (Claude) reduce the rate but do not eliminate it.
Voice flattening
Brand voice tools learn from samples. Most teams supply five to ten samples that are themselves derivative of category convention. Output regresses toward the mean of marketing English: confident, mildly enthusiastic, pattern-matched to the LinkedIn post that ranks. The fix is editorial discipline refreshed quarterly with the strongest recent work, not a one-time configuration during onboarding.
Integration tax
Every tool added to the stack is an authentication boundary, a billing line, and a context switch. The all-in stack of Frase plus Jasper plus Surfer plus Grammarly routinely runs $300-500 per seat per month. Solo creators rarely justify it. Agencies usually do. Lean teams of two to four sit in the awkward middle and frequently overpay.
Stack by team size
Stack composition correlates almost entirely with team size and publishing cadence, not industry vertical. The chart below decomposes monthly stack cost across four team archetypes.
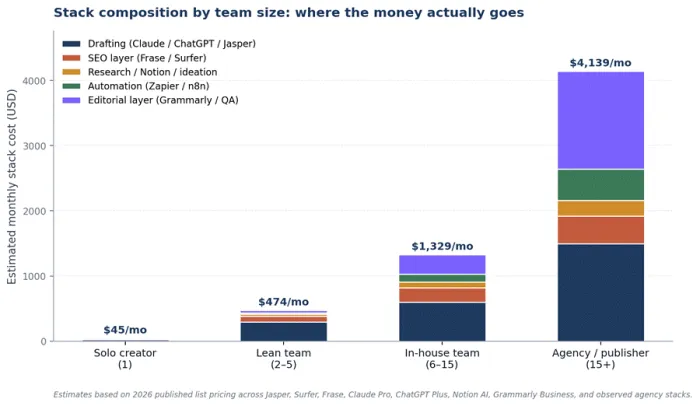
Figure 4. Stack composition by team size. Decomposes total monthly spend into drafting, SEO, research, automation, and editorial layers.
Solo creators get the best ROI from Claude plus Frase Solo plus Notion AI at roughly $45 per month. Lean teams overpay if they jump straight to Jasper Pro plus Surfer; the better play is Claude or ChatGPT plus Frase Basic plus Surfer, then add Jasper only if brand-voice governance becomes a real problem.
Review sentiment
Aggregate ratings cluster between 4.6 and 4.9, which makes the headline number nearly useless. The credible signal is what users complain about, since vendors with similar averages often differ sharply on which weaknesses persist across review cohorts.
Table 2. Paraphrased synthesis of G2, Capterra, Trustpilot, and creator hands-on reviews from late 2025 to early 2026.
| Tool | G2 | Capterra | What users praise | What users complain about |
|---|---|---|---|---|
| Jasper | 4.7 / ~1,700 | ~4.8 | Brand voice training. Multi-channel campaign workflows. Knowledge Base reduces hallucinations. | 1,500-char lookback breaks long-form. Hallucinates 15-20% of factual claims. Per-seat pricing creep. |
| Surfer SEO | 4.8 / ~537 | 4.9 / ~417 | Content Editor scoring. Topical Map for cluster planning. Content Audit ROI on refreshes. | Pricing steep for solos. Score-to-rank correlation is loose. Niche topics produce thin data. |
| Frase | 4.8 / ~300 | ~4.8 | Fastest brief generation in market. GEO score and AI Search Tracking are 2026 differentiators. | Long-form drafting weakens past 1,500 words. UI lag at higher volumes. Eight-language support only. |
| Claude Pro | Not on G2 | Not on G2 | Long-form coherence with 200K context. Less template-y output (the 'lived-in quality'). | Pro rate limits cut you off mid-refinement. No SEO scoring, no marketing wrapper. |
| ChatGPT Plus | Not on G2 | Not on G2 | GPT-5.4 with 1M context. DALL-E. Voice mode. Real-time browsing. Custom GPTs ecosystem. | Default output has the AI-slop signature. Brand voice resets between sessions on Plus. |
| Copy.ai Pro | 4.7 / ~190 | ~4.5 | Short-form template breadth. GTM workflows. Free tier works for ideation. | Long-form quality regression in late-2025 reviews. Brand voice trails Jasper meaningfully. |
GEO: the 2026 shift
The largest single change in blog workflows this year is not new drafting models. It is the move from optimizing for Google rank to optimizing for AI citation. ChatGPT, Perplexity, Google AI Overviews, and Gemini collectively answer a meaningful share of informational queries before the user sees a blue link.
What AI engines reward: clear definitions, structured factual claims, specific numerical data, citation-worthy specificity, topical clusters that establish expertise. What they punish: vague generalities, unsourced statistics, listicle padding, content that mirrors competitors too closely. Frase's GEO score and AI Search Tracking, plus Surfer's AI Tracker, are the first measurement tools for this. The opportunity window will close fast.
The final take
The defensible answer to how creators should use AI for their blog stopped being “pick one tool” sometime in 2024. In 2026 the answer is to map the full pipeline and assign tools to specific stages: research, outlining, drafting, optimization, and revision. You might lean on one platform for SERP and AI search analysis, another for long-form drafting, and a third for on-page optimization, but you accept that none of them can write the kind of piece that makes a reader bookmark you. The real leverage is in using AI to collapse pattern-matching work while you keep ownership of angles, arguments, and evidence.
Within that context, a specialist hub like Writenexa makes the most sense when it is treated as the place where that pipeline is orchestrated rather than as a magic “write my blog” button. Briefs, topic research, entity lists, and structural decisions live there; external models handle scaffolding and rewrites; human editors still decide which claims stand, which examples stay, and which sections get cut. Brand voice systems will keep trying to flatten you, SEO scorers will keep rewarding sameness, and drafting models will continue to hallucinate a non-trivial share of facts. The creators actually pulling ahead in 2026 are not the ones publishing the fastest, but the ones whose archives still read like a person did the thinking and used AI deliberately to support that, not to skip it.





