
Most teams scaling blog content with AI are not solving a writing problem. They are solving an orchestration problem and pretending it is a writing problem, which is why the bills get larger and the rankings stay flat. Generation is the cheapest part of the chain now; the expensive parts are research that survives editorial scrutiny, briefs that align human writers with SERP reality, optimization scoring tied to current ranking signals, and quality control that catches the failure modes the model hides confidently. A scalable system, then, is a sequence of small wagers on different vendors, each chosen because it does one job better than the generalist alternative. What follows is the architecture, the tools that earn their seat, and the conditions under which each one stops working.
FOUNDATIONS • The architecture before the tooling
A scalable blog system has six functional layers, and the trap most operators fall into is collapsing two or three of them into a single subscription. The layers are: keyword and intent discovery, SERP-grounded brief construction, drafting, on-page optimization scoring, editorial and detection QA, and publish-side automation. Each layer has different update cadences, different failure modes, and different cost curves. Treating them as one workflow inside one tool is what produces the familiar pattern of teams publishing twenty articles a month and watching organic traffic move sideways.
The tools below cover the four layers where AI has materially changed the unit economics: brief construction (Frase), optimization scoring (Surfer SEO), drafting at the model level (Claude API), team-scale drafting with brand voice constraints (Jasper), and QA detection (Originality.ai). Keyword discovery still belongs to Ahrefs or Semrush, and publish automation still belongs to Zapier or Make on top of WordPress, Sanity, or whatever CMS the team has standardized on. Those two layers have not been disrupted by generative AI in any commercially meaningful way, and any analysis claiming otherwise is selling something.
LAYER 1:
RESEARCH AND BRIEF CONSTRUCTION • Frase.io and the brief as the actual product
Frase’s defining feature is not its AI writer. The AI writer is mediocre by 2026 standards, and that is a fact widely confirmed in user reviews on G2 and on its own community forum. The defining feature is what the brief contains and how fast it arrives: under sixty seconds, you get the top twenty SERP results parsed into headings clustered by frequency, the average word count of the ranking set, the People Also Ask question cluster, citation-eligible sources, and an outline scaffold. That replaces roughly forty to sixty minutes of manual SERP triage per keyword, which is the actual bottleneck most content teams refuse to admit they have.
What makes the brief workable
The grouping logic is the underrated part. Rather than dumping ten outlines side by side, Frase counts how often a given heading concept appears across the top ten and ranks them. A writer can see at a glance that, say, eight of ten ranking pages discuss a specific objection and can decide whether to include it as a section, a callout, or skip it entirely. The decision becomes cheap, and a cheap decision is the only kind that scales across a team of five freelancers.
Where the workflow breaks is keyword difficulty. The KD numbers Frase surfaces drift noticeably from Ahrefs and Semrush data, and experienced operators ignore them. The site audit and AI visibility tracking added in the 2025-2026 platform expansion are useful but secondary; teams adopt Frase for briefs and tolerate the rest. The AI writer’s output sits in roughly the same band as a fine-tuned GPT 3.5, which is to say competent for a first paragraph and unreliable past the third.
Pricing structure and what scales with each tier
| Plan | Monthly / Annual | Article and brief volume | Best fit |
| Solo | $15 / $12 (annual) | 4 article projects, 1 seat, 1 domain | Solo SEO publishing one article per week |
| Basic | $45 / $38.25 (annual) | 30 articles, 1 seat, page tracking for 1 site | Freelance writer or in-house specialist |
| Team | $115 / $97.75 (annual) | 75 projects, 3 seats (+$25 per extra), unlimited sharing | Agencies and 3-to-9 person content teams |
| Pro Add-on (any plan) | +$35 / month | Unlimited AI words, removes the writer cap | Teams that draft inside Frase |
Pricing as published on frase.io and verified through independent reviewers, March-April 2026. Annual billing applies a roughly 15 percent discount.
Adoption signal and where it sits in the market
G2 lists Frase at 4.8 stars across roughly 320 verified reviews; Capterra is in the same band. The customer list disclosed on Frase’s own pricing page (Coursera, GitLab, Oracle, Toptal, Thomson Reuters, Under Armour) is more useful than the rating, because it shows that brief generation as a category has crossed into enterprise content operations. The persistent complaint, repeated almost verbatim across review platforms, is that the headline price omits the Pro Add-on cost; teams that draft inside Frase should plan for $80 a month minimum on the Basic tier.
LAYER 2:
OPTIMIZATION SCORING • Surfer SEO and the seductive logic of a content score

Surfer scrapes the top SERP results for a target query, runs NLP analysis across roughly 500 on-page signals, and produces a real-time content score from 0 to 100. The number is the product. Writers chase it the way pilots chase glide slope, and the score is, on balance, useful: pages optimized to a Surfer score of 67 or higher do correlate with first-page placement on competitive queries, particularly in B2B SaaS, e-commerce category pages, and tech publishing. The correlation is real. The causation is partial.
The score rewards looking like the average of the top ten, which is precisely the wrong target if the top ten are themselves drifting toward generic optimization.
That trade-off is the central tension of any correlational SEO tool, and it is more pronounced in Surfer than in lighter optimizers. Heavy users notice that articles written to a 90 score sometimes underperform articles written to 65 with sharper editorial framing, because the score does not weight thesis, voice, or original reporting. Surfer’s 2025 Humanizer add-on is an oblique acknowledgement of the problem: the tool now sells a feature to undo the homogenization its own scoring encourages.
Pricing, with the volume math the website does not run for you
| Tier | Cost (annual / monthly) | What you actually get for the money |
| Essential | $79 / $99 | 30 Content Editor articles, 5 AI articles, 200 tracked pages, 5 seats |
| Scale | $175 / $219 | 100 Editor articles, 20 AI articles, 1,000 tracked pages, 10 seats, API, white-label reports |
| Enterprise | Custom | Unlimited seats, SSO, dedicated CSM, priority support, custom limits |
| AI Tracker (add-on) | +$95 / month | Tracks brand visibility in ChatGPT, Perplexity, Google AI Mode (25 prompts) |
Surfer SEO public pricing, verified February-April 2026. Unused Content Editor credits do not roll over on monthly billing; annual plans grant the full year batch up front.
The competitive position, told without flattery
| Tool | Entry price | Where it wins against Surfer | Where Surfer wins |
| Clearscope | ~$170 / mo | Cleaner term coverage analysis; preferred by editorial teams | Half the price; integrated AI writer; Google Docs add-in |
| Frase | $15 / mo | Brief generation depth; AI visibility tracking included | More granular NLP density and entity scoring |
| MarketMuse | $149 / mo | Topical authority modeling across whole site inventories | Faster per-article workflow; lower learning curve |
| NeuronWriter | €23 / mo | Substantially cheaper for solo operators | Better UI, integrations, and customer support |
Surfer’s G2 standing is 4.8 across 537 verified reviews; Capterra rates it 4.9 across 414 reviews. The praise concentrates on workflow speed and Content Editor usability. The negatives concentrate on three specific patterns: keyword research data that operators stop trusting after a quarter or two, AI articles that need substantial human editing despite costing additional credits, and pricing perceived as steep for solo bloggers. Reddit threads in r/SEO are notably more critical than the formal review platforms, and that gap (between sponsored review platforms and practitioner forums) is itself a useful signal across this entire category.
LAYER 3:
DIRECT LLM ACCESS • Claude API as the drafting layer when SaaS feels like overhead
Most published comparisons evaluate Anthropic’s Claude as a chatbot. For a content operation, that framing is wrong. The relevant question is whether the per-token API economics and long-context behaviour produce a better cost per published article than a Jasper or Surfer subscription, given that the team has someone who can write a Python script and call an HTTP endpoint. The answer, for most teams publishing more than fifteen articles a month with editorial oversight, is yes.
The pricing card, and why it reframes the unit cost question
| Model | Input ($/M tokens) | Output ($/M tokens) | Use in a blog stack |
| Haiku 4.5 | $1.00 | $5.00 | Outline expansion, tag generation, FAQ drafting |
| Sonnet 4.6 | $3.00 | $15.00 | First-draft long-form, editorial revisions |
| Opus 4.7 | $5.00 | $25.00 | High-stakes pillar content, technical reviews |
Source: Anthropic API pricing page, verified May 2026. Prompt caching reduces cached input by up to 90 percent; Batch API applies a flat 50 percent discount on asynchronous workloads.
What a 1,500 word article actually costs
A 1,500-word draft on Sonnet 4.6 typically consumes around 8,000 input tokens (system prompt, brief, source excerpts) and produces about 2,500 output tokens. Math: $0.024 input plus $0.0375 output, total roughly four cents per draft. Run the same job through Opus 4.7 with a longer instruction set and citation grounding, and the cost climbs to about thirteen cents. Even at scale (200 drafts a month), the raw model cost stays under $30. The expensive line items in any LLM-driven blog operation are not tokens; they are the engineering hours to wire prompt templates, the editorial hours to revise drafts, and the prompt-caching architecture that cuts the input bill by 70 to 90 percent on repeat-context calls.
Where a raw API beats a packaged tool, and where it does not
The API approach wins when the team has at least one technical contributor, when content categories vary enough that templated workflows feel constraining, and when prompt caching can be exploited (style guides, brand voice documents, and source material loaded once and reused for thousands of calls). It loses when the buyer is a non-technical marketing manager who needs an interface, when the workflow requires built-in collaboration and approval flows, or when SOC 2 attestation needs to live inside a vendor wrapper rather than the team’s own infrastructure. The April 2026 launch of Opus 4.7 raised effective costs by zero to thirty-five percent on identical text due to a tokenizer change, and any team migrating from 4.6 should benchmark on real traffic before assuming the headline rate.
Failure modes are specific. Claude is markedly less prone to hallucinating citations than competitors when given grounded sources, but it will produce confident summaries of sources it has not actually read if the prompt does not enforce extraction. It is also verbose by default; teams that publish 1,200-word posts and use Sonnet without strict length constraints will generate 1,800 words, which is a 50 percent overage on the output bill. None of this is hard to fix. All of it has to be fixed.
LAYER 3 (ALTERNATIVE):
TEMPLATED DRAFTING WITH BRAND VOICE • Jasper, the marketing hub that bet against general AI
Jasper’s strategic position in 2026 is the most interesting story in this category. The product launched as a thin wrapper over GPT in 2021 and was, for a while, the clear category leader. The release of ChatGPT in November 2022 should have killed it. It did not, because Jasper rebuilt itself from a writing tool into a marketing operations platform: brand voice profiles, knowledge assets, agentic workflows, SOC 2 compliance, audience definitions, and an LLM-agnostic backend that can route to whichever model best fits a given task. The premium pricing is now defended not by output quality (general LLMs match it) but by governance and consistency tooling that solo subscriptions to ChatGPT or Claude do not provide.
The Pro versus Business divide is sharper than the website admits
| Feature | Creator ($39 / $49) | Pro ($59 / $69) | Business (custom) |
| Brand Voices | 1 | 2 (extendable) | Unlimited |
| Knowledge assets (RAG grounding) | 3 | 5 | Unlimited |
| API access | No | No | Yes |
| Custom AI Agents (Studio) | No | Limited | Full |
| SSO and admin controls | No | No | Yes |
| Reported real-world cost | $39–$49 / mo | $59–$69 / seat / mo | $250–$3,000+ / mo |
Pro plan starts at one seat; additional seats are billed independently. Business pricing reported through Vendr transaction data shows wide variance based on seat count, term length, and prepayment.
Why marketing teams still pay three times the cost of a general LLM
Brand voice consistency, treated as the moat. Jasper’s voice profiles ingest existing assets and reproduce tone across thousands of generations with materially less drift than prompted ChatGPT or Claude. For a team with twelve writers across eight content channels, that consistency is operationally cheaper than enforcing it with style guides and human review. Whether it is cheaper than three engineers building a Claude wrapper with the same controls is another matter, and it is the question that determines whether Jasper’s renewal happens or does not.
The critique that recurs in G2 reviews (Jasper holds 4.7 stars across roughly 1,855 verified entries, Capterra at 4.8) is consistent: output sometimes feels generic, the platform requires meaningful upfront configuration, and the pause-subscription policy locks users out of paid usage with little flexibility. Sentiment is fundamentally positive on workflow speed and template breadth; sentiment turns negative on the gap between Pro features and Business features, which the company does not advertise transparently. Solo creators consistently conclude that ChatGPT Plus or Claude Pro at $20 a month is sufficient. Marketing teams of five or more, particularly in regulated industries, conclude the opposite.
Jasper is the right purchase when content production is multi-channel, brand voice is a board-level concern, and at least one stakeholder needs an interface rather than an SDK. It is the wrong purchase when the actual job is two writers producing twenty articles a month with normal editorial review.
LAYER 4:
QA DETECTION AND FACT VALIDATION • Originality.ai sits at the gate, not in the workshop
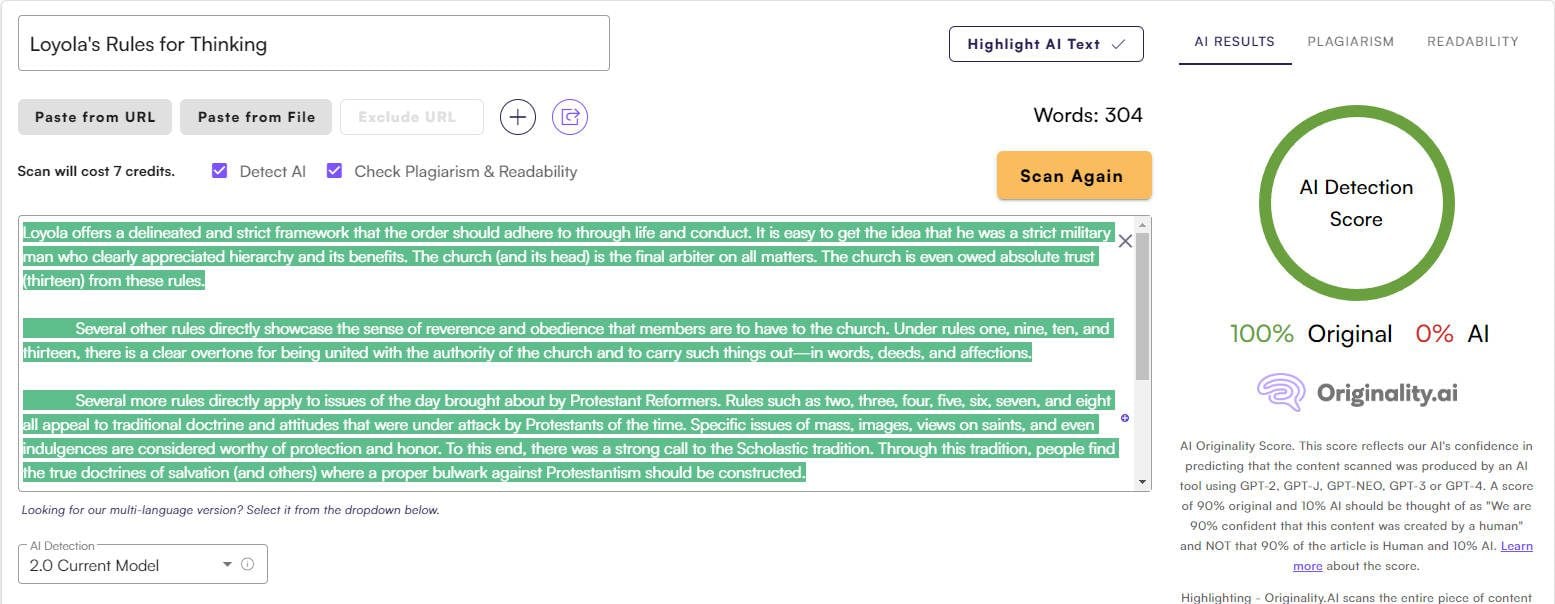
AI detection is the messiest sub-category in this stack. Detector accuracy is noisy on humanized text, false positives have already cost real writers real assignments, and the entire premise (that AI text can be reliably identified after light editing) is contested by independent researchers. Originality.ai is, despite the noise, the closest thing the category has to a defensible publisher-grade tool. It scores at the top of the band alongside Turnitin and Winston in independent testing on raw model output and is the only commercial detector that bundles plagiarism checking, readability scoring, and a fact-checking module on the same credit base.
Credit math worth memorizing: one credit covers 100 words of AI or plagiarism scanning, and 10 words of fact checking. The Base plan at $14.95 a month allocates 2,000 credits, enough for roughly 200,000 words of AI scans (about 130 to 150 articles at 1,500 words each). The Pro tier at $179 a month allocates 15,000 credits and adds team management, API access, and 365-day report retention. The pay-as-you-go option at $30 for 3,000 credits suits teams running quarterly audits rather than continuous QA.
| Use Originality when… | Skip it when… |
| • You commission writers and need a defensible AI screen on incoming work | • Your only goal is to bypass detection rather than verify originality |
| • You publish in regulated verticals where attribution matters legally | • Your team writes everything in-house and you trust the process |
| • You want plagiarism, AI, fact, and readability checks on one credit pool | • You publish content already humanized through a rewriting pipeline |
| • You need an API to enforce QA programmatically before publish | • You expect detection to function as policy enforcement on its own |
What the reviews actually say once you read past the rating
On Capterra, Originality holds a high aggregate rating across roughly 100 verified reviews; the consistent praise is for support responsiveness and the per-sentence highlighting in detection reports. The consistent complaint is price for low-volume users (the $14.95 entry tier feels reasonable; the $179 Pro tier is hard to justify for teams scanning fewer than 500 articles a month). The deeper structural critique, repeated by several agency users, is that detection accuracy collapses on text that has been run through a humanizer or paraphraser, which is the exact attack surface the tool is supposed to defend against. That is not an Originality problem specifically; it is a detection-category problem. Treating any detector as a final gate rather than a screening signal is a category error operators stop making after their first false positive on a senior writer’s draft.
QUANTITATIVE COMPARISON • Cost per published article: the only spreadsheet that matters
The simplest way to evaluate any of these tools is to compute the all-in cost per published article at a target monthly volume, including the people-hours saved or required. The figures below assume a 1,500-word article with full editorial review, mid-market US labour rates ($35 per hour blended writer plus editor), and the realistic time savings each tool delivers in deployed teams. Tool subscriptions are spread across the article volume in the row.
| Stack pattern | Tools | Monthly tooling cost | Articles / month | All-in $ / article |
| Solo operator | Frase Solo, Claude Pro, Originality Base | $50 | 8 | ~$170 |
| Lean content team | Frase Basic + Pro Add-on, Surfer Essential, Claude API, Originality Base | $240 | 25 | ~$135 |
| Mid-market agency | Frase Team, Surfer Scale, Jasper Pro (3 seats), Originality Pro | $705 | 80 | ~$95 |
| Enterprise content ops | Surfer Enterprise, Jasper Business, Frase Team, Claude API at scale, Originality Pro | $2,500+ | 250+ | ~$70 |
Cost per article includes blended writer-and-editor time per article (estimated 2.5 to 3.5 hours after AI assistance). Tooling costs are amortized across volume; labour dominates the per-article figure at every tier, which is the point.
The table reveals the unflattering truth of the category: the cost per article does not collapse as volume rises because tooling was never the dominant line item. Editorial labour was, and remains, the constraint. Teams that buy a $700-a-month stack and continue to spend three editor-hours per article will not see economics improve materially over teams that buy a $50 stack and do the same. The lever that moves the number is reducing editor time per article, which only happens when briefs are sharper, drafts arrive closer to publication-ready, and QA fails fast on the bad ones rather than burning hours on revisions.
COMPOSITION • Three stack patterns that actually work in production
The lean independent stack
Frase Solo for briefs ($15), Claude Pro for drafting ($20), Originality Base for QA ($14.95). Total under $50 a month. Suited to one-person operations publishing eight to twelve articles a month. The trade-off accepted here is the absence of formal optimization scoring (no Surfer or Clearscope), which is acceptable for low-competition niches and unacceptable for B2B SaaS or e-commerce category targeting.
The mid-volume editorial stack
Frase Basic with the Pro Add-on ($80) for briefs and AI drafts, Surfer Essential ($79 annual) for optimization scoring, Claude API metered ($30 to $60) for batch revisions, Originality Base ($14.95) for QA. Roughly $200 to $235 a month. This is the pattern that produces 25 to 40 articles a month with two writers and one editor. The configuration deliberately avoids Jasper because a two-person team does not need brand voice governance; one editor enforces it for free.
The agency or enterprise content stack
Surfer Scale ($175 annual) plus Frase Team ($98 annual) plus Jasper Pro at three to five seats ($177 to $295) plus Originality Pro ($136.58 annual) plus a Claude API line for any custom drafting work. Roughly $600 to $750 a month before custom enterprise pricing kicks in. Justifiable above 75 articles a month or when client-facing white-label reporting becomes a contractual requirement. Below that volume, the agency stack is overengineered, and the cost per article math turns ugly fast.
SYNTHESIS • Decision guidance
Three principles emerge from the analysis above and are worth restating without hedging. First: no single tool wins this category, because the layers have different jobs and different update cadences, and the vendors that pretend otherwise are selling integrated bundles at a premium that the math does not support outside the enterprise tier. Second: the cost lever that actually moves per-article economics is not subscription cost; it is the time editors spend per article, and the tools worth paying for are the ones that reduce that time on the briefs and the QA pass, not the ones that promise to draft faster. Third: the pricing card is rarely the real price. Frase’s headline rate omits the Pro Add-on. Surfer’s monthly credits do not roll over. Jasper’s Business tier is opaque by design. Claude’s tokenizer change in Opus 4.7 raised effective costs by up to 35 percent on identical text. Build the stack against the real number, not the marketing one.
For an operator picking a starting point: if the bottleneck is research, start with Frase. If the bottleneck is ranking on competitive queries, start with Surfer. If the bottleneck is brand voice across multiple writers, start with Jasper. If the team has engineering capacity and the bottleneck is cost at high volume, start with the Claude API and build the wrapper. In every case, layer Originality.ai as the QA gate before publish; it is the cheapest insurance in the stack and the easiest to justify when one bad piece slips through and a senior editor has to explain it on a Monday call.
That is also why platforms like WriteNexa increasingly matter for smaller marketing teams and independent operators. The challenge is no longer finding AI tools. It is understanding how to combine them into a repeatable content workflow that stays efficient as publishing volume scales. The tools are the easy part. The discipline to keep the layers separate, and the willingness to fire any vendor whose seat the workflow has outgrown, is the part that determines whether the operation scales or just becomes more expensive.





